
La Confusion Matrix résume les résultats d'une analyse prédictive effectuée par un modèle de machine learning pour une tâche de classification. Elle permet de mesurer la performance du modèle et de comprendre les erreurs.
Dans le cadre du machine learning, nous faisons souvent référence à la précision d'un modèle pour décrire sa performance. Mais en dehors de la précision, il existe un taux d'erreur ou d'autres informations qu'il est possible de visualiser dans la Confusion Matrix.
Qu'est-ce que la Confusion Matrix ?
Une Confusion Matrix est aussi appelée matrice de confusion ou tableau de contingence. Il s'agit d'un outil utilisé dans le cadre du machine learning pour afficher les résultats d'une analyse prédictive. La matrice de confusion peut également être utilisée dans la data science, le data mining ou les analyses statistiques.
Mais en termes de machine learning, elle permet d'analyser les performances d'un modèle lors d'une tâche de classification. Entre autres, la Confusion Matrix compare les valeurs réelles à valeurs prédites par le modèle. Elle permet également de visualiser des paramètres tels que la précision, l'exactitude ou la spécificité.
À la différence d'autres outils de mesure, la matrice de confusion n'affiche pas uniquement la précision. Autrement dit, le tableau offre une visualisation plus complète de la performance du classificateur. Par exemple, il permet de voir le taux d'erreurs ou les types d'erreurs et de les expliquer. De ce fait, il compare les exemples classés correctement par rapport aux exemples mal classés. Ces valeurs sont classées en tant que faux positifs, vrais positifs, faux négatifs et vrais négatifs.
Comment fonctionne la Confusion Matrix ?
Dans un problème de classification, un modèle de machine learning doit apprendre à prédire la classe d'une entrée, ce qui implique l'existence d'un référentiel. Ensuite, le calcul de la Confusion Matrix nécessite l'utilisation de deux ensembles de données. Le premier ensemble consiste en un jeu de données de tests, aussi appelé test dataset. Le deuxième ensemble qui sert de référentiel correspond donc à des données de validation ou validation dataset.
La classification n'est possible que lorsqu'il y a deux classes ou plus. Le modèle effectue donc un calcul pour prédire les classes des test dataset. Le tableau de contingence affiche les différentes valeurs, à savoir le nombre de prédictions correctes et incorrectes pour chaque classe.
Interprétation
Pour une classification avec deux classes, la Confusion Matrix s'affiche sous forme d'un tableau 2×2. Le nombre de lignes et de colonnes varie en fonction du nombre de classes. Les lignes correspondent aux valeurs réelles d'une classe tandis que les colonnes indiquent les valeurs prédites. Pour interpréter le tableau, il suffit d'examiner l'intersection des lignes et des colonnes. Le coin supérieur gauche indique le nombre de prédictions positives correctes, tandis que le coin supérieur droit indique les faux positifs. Par ailleurs, le coin inférieur gauche affiche les faux négatifs tandis que le coin inférieur droit affiche les prédictions négatives correctes. Dans le cas où la matrice de confusion est un tableau de 3×3 ou plus, elle se lit de manière diagonale allant du haut à gauche au bas à droite.
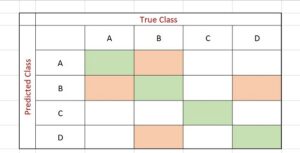
Comment analyser la performance d'une Confusion Matrix ?
Afin de tirer des informations nécessaires d'une Confusion Matrix, notamment les différentes métriques, nous devons d'abord comprendre les termes utilisés.
Le jargon de la matrice de confusion
Tout comme son nom, les terminologies de la Confusion Matrix peuvent créer une confusion. Il existe deux types de résultats corrects (TP et TN) et deux types d'erreurs (FP et FN).
Les vrais positifs
Les vrais positifs ou true positive (TP) indiquent les valeurs correctement classées positives. Prenons un exemple simple. Pour un test de dépistage de la COVID-19, la valeur TP indique que le modèle a classé un patient comme étant positif, est c'est vrai.
Les faux positifs
Les faux positifs ou false positive (FP) indiquent les valeurs classées positives par erreur. Dans le cas de notre exemple, une personne testée positive est en réalité négative.
Les vrais négatifs
Les vrais négatifs ou true negative (TN) correspondent aux valeurs correctement classées négatives. Toujours pour le même exemple, un patient a été testé négatif à la COVID-19 et il n'est réellement pas atteint.
Les faux négatifs
Enfin, les faux négatifs ou false negative (FN) indiquent les valeurs classées négatives par erreur. Ici donc, une personne aurait été testée négative, mais il est en réalité atteint par la maladie.
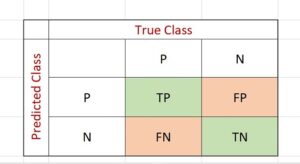
Les métriques de la Confusion Matrix
Pour interpréter plus facilement la Confusion Matrix et évaluer la performance du modèle, il existe différentes métriques qui peuvent être utilisées.
rappel
En termes de classification, le recall ou rappel correspond au pourcentage d'exemples positifs qu'un modèle a automatiquement classé parmi tous les exemples positifs. Le calcul du rappel se fait par la division de la valeur TP par la valeur FN combiné au total d'exemples positifs. Il peut aussi être appelé taux de réussite.
Precision
Comme le rappel, la précision correspond à un pourcentage des exemples positifs. Toutefois, ce paramètre s'intéresse aux données étiquetées positives par le modèle. Autrement dit, ici, le nombre total d'exemples positifs est divisé par la somme des TP et des FP.
Score F1
Le score F1, également connu comme F-measure, permet de mesurer la précision et le rappel en même temps grâce à la moyenne harmonique. Il se calcule en doublant le produit des deux paramètres, puis en les divisant par leur somme.
Accuracy
Le paramètre d'accuracy permet de déterminer le taux de prédiction correct parmi toutes les classes positives et négatives. Il se calcule en divisant la somme des TP et des TN par le nombre total d'exemples.
Specificité
La spécificité ou specificity s'intéresse au taux d'exemples négatifs classés par le modèle. Pour le calculer, il faut diviser le nombre total d'exemples négatifs par la somme des FP et des TN. Il est aussi appelé TNR ou true negative rate.
Certes, il est possible de calculer toutes les métriques de la Confusion Matrix manuellement. Néanmoins, la plupart des bibliothèques de machine learning, dont Python, fournissent des outils qui permettent de les générer automatiquement.
- Partager l'article :
