
Le machine learning aide ces chercheurs à restructurer les visages dans les vidéos sans provoquer des artefacts.
Il existe de nos jours un nombre incalculable de logiciels permettant de retoucher les photos et les vidéos. Mais le remodelage d'un corps ou d'un visage n'est pas toujours facile à faire. Par ailleurs, les résultats sont rarement satisfaisants en raison des artefacts qui trahissent les modifications effectuées et qui affectent la qualité des images de sortie.
Se baser sur le machine learning pour restructurer les visages dans les vidéos
Effectuer une transformation du corps ou du visage dans une photo est déjà une tâche difficile de la vision par ordinateur. Mais dans une vidéo, cela devient encore plus complexe étant donné que le sujet ne reste pas immobile.
Dans un article publié il y a quelques jours, un collectif de recherche a présenté une nouvelle méthode pour restructurer les visages dans les vidéos à l'aide du machine learning. L'équipe a rassemblé des chercheurs de l'université de Zhejiang, en Chine et un de l'université de Bath, au Royaume-Uni.
La technique consiste à élargir ou à rétrécir la forme du visage de manière réaliste et sans provoquer d'artefacts. Traditionnellement, la méthode utilisée est l'utilisation des effets spéciaux numériques (CGI). Mais cela implique de recréer entièrement le visage à l'aide de plusieurs procédures complexes et coûteuses.
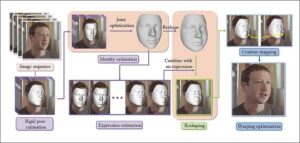
La nouvelle technique, par contre, extrait en 3D les informations paramétriques du visage. Elle les intègre par la suite dans un réseau neuronal d'apprentissage automatique.
Extraire, estimer, remodeler
L'article décrit le processus qui se déroule en plusieurs étapes. Tout d'abord, les chercheurs ont extrait la vidéo en séquences d'image. Cela leur a permis d'estimer une pose rigide du visage ainsi que d'autres images représentatives de l'identité. Par la suite, à l'aide d'une technique de régression linéaire, le modèle a évalué l'expression afin de paramétrer le remodelage. En outre, avant et après le remodelage, ils ont cartographié le visage en 2D à l'aide d'une fonction distance signée (SDF).
Pour déformer le visage, les chercheurs ont utilisé une technique issue d'un projet de 2020 intitulé Deep Shapely Portraits (DSP). Mais au lieu de restructurer le visage dans une image monoculaire, ils ont étendu la méthode sur l'ensemble des séquences d'images dans les vidéos. Comparés aux vidéos résultantes de la méthode DSP, les résultats de la nouvelle méthode étaient alors plus cohérents.
- Partager l'article :
