
Le test de Turing est un test qui consiste à vérifier la capacité d’une machine à faire preuve de signes d’intelligence humaine. Encore aujourd’hui, ce test fait figure de standard pour déterminer l’intelligence d’une machine.
Le Test de Turing est le repère historique pour mesurer l’intelligence artificielle. Créé par Alan Turing en 1950, il évalue si une machine peut imiter un humain lors d’une conversation. Aujourd’hui, avec les IA avancées comme GPT‑4 et GPT‑4.5, ce test reste au cœur des débats sur la frontière entre simulation et véritable intelligence. Découvrez son histoire, son fonctionnement et son rôle dans l’évolution des intelligences artificielles modernes.

Qu’est-ce que le Test de Turing ?
Le Test de Turing est une expérience pensée par le mathématicien britannique Alan Turing en 1950. Son objectif est de déterminer si une machine peut se faire passer pour un humain lors d’une conversation.
Concrètement, un évaluateur dialogue par écrit avec deux interlocuteurs, dont l’un est une intelligence artificielle. S’il n’arrive pas à distinguer l’humain de la machine, alors cette dernière a « réussi » le test.
À l’origine appelé Imitation Game, ce protocole a ouvert la voie à la réflexion moderne sur l’intelligence artificielle.
Il ne mesure pas une conscience réelle, mais plutôt la capacité d’un programme à imiter un comportement humain crédible.
Aujourd’hui encore, ce test représente un repère incontournable dans l’histoire de l’IA, même si les chatbots modernes et les modèles de langage comme GPT-4 ou GPT-4.5 ont largement dépassé son cadre initial.
Le Test de Turing continue donc de symboliser la frontière entre intelligence humaine et machine.
Pourquoi le Test de Turing est-t-il important aujourd’hui ?
Même si le Test de Turing date de plus de 70 ans, il garde une place centrale dans les discussions sur l’intelligence artificielle. Pourquoi ?
Parce qu’il pose une question toujours actuelle ci-après : une machine peut-elle réellement penser ou se contente-t-elle de simuler ?
Effectivement, les IA génératives, comme GPT-4 et Google LaMDA, tiennent des conversations de plus en plus naturelles. De ce fait, ce test est un point de comparaison accessible et universel.
En plus de cela, il est aussi un outil pédagogique. Concrètement, il permet d’expliquer au grand public la différence entre imiter l’intelligence et comprendre vraiment.
Certes, ses limites sont nombreuses, particulièrement face à des modèles multimodaux capables de traiter du texte, de la voix et des images.
Mais le Test de Turing conserve sa pertinence comme symbole fondateur. Il rappelle que l’IA n’est pas juste une prouesse technique, mais également un enjeu philosophique, éthique et sociétal.
Alan Turing, le créateur du test de Turing

Ce test a été conçu par Alan Turing, mathématicien et professeur à l’Université de Manchester, en 1950.
Il a été présenté pour la première fois dans l’article historique intitulé « Computing Machinery and Intelligence », qui se concentrait sur la question clé : « Les machines peuvent-elles penser ? ».
Ce texte fondateur explore la possibilité d’une intelligence artificielle en proposant un test pratique pour déterminer si une machine peut imiter un comportement humain de manière convaincante.
Dès les années 1940, Turing a réfléchi à la question de l’intelligence des machines, notamment dans son rapport de 1947 intitulé « Intelligent Machinery », où il pose les bases du concept.
Dans ce rapport, Turing explore les possibilités de créer des machines capables d’adopter des comportements intelligents, préfigurant ainsi le célèbre Test de Turing.
L’article de 1950 marque un tournant, introduisant l’idée de l’« Imitation Game », où un juge interagit avec un humain et une machine via des échanges textuels.
Si le juge est incapable de distinguer l’humain de la machine, cette dernière est considérée comme ayant « réussi » le test.
Cette première version du test a évolué au fil des années. En 1952, une nouvelle itération consistait à ce que la machine persuade un jury qu’elle est humaine.
Cette méthode est devenue la version la plus couramment utilisée aujourd’hui dans les évaluations d’intelligence artificielle.
Tout comme l’on cherche à évaluer la crédibilité d’une machine, de nombreux utilisateurs s’appuient sur des analyses d’experts pour vérifier la fiabilité des plateformes en ligne, à l’image des conseils fournis par Will Win gg.
ELIZA et PARRY : les deux premiers programmes capables de passer le Test de Turing
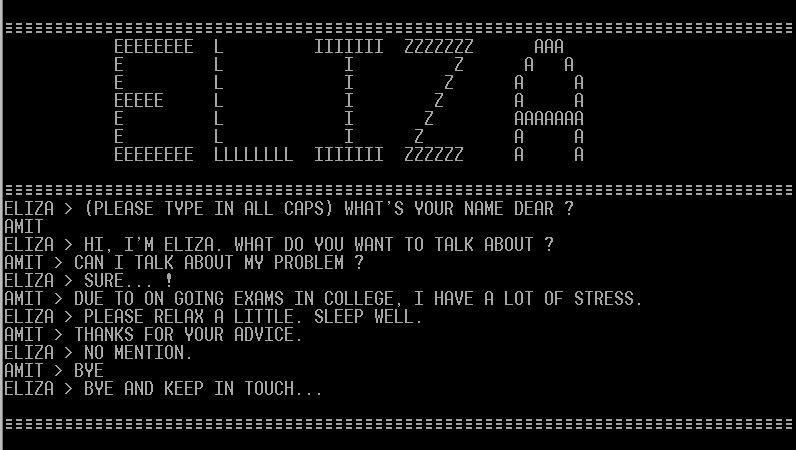
ELIZA et PARRY sont les premiers programmes à avoir réussi à tromper des humains lors de conversations simulées.
Ils relèvent ainsi d’une forme primitive du Test de Turing. En 1966, Joseph Weizenbaum développa ELIZA, un programme qui simule une conversation humaine à travers des échanges textuels.
ELIZA fonctionne en analysant un texte à la recherche de mots-clés pour générer des réponses adaptées. Lorsqu’aucun mot-clé pertinent n’est détecté, le programme produit des réponses génériques.
Le rôle d’ELIZA était de créer l’illusion d’une compréhension humaine, bien que le programme n’ait aucune réelle compréhension du contenu des échanges.
Ce stratagème permit à ELIZA de convaincre de nombreuses personnes qu’elles conversaient avec un véritable humain, ce qui fait de lui l’un des premiers programmes à « passer » une version primitive du Test de Turing.
En 1966, Joseph Weizenbaum développa ELIZA, un programme qui simule une conversation humaine à travers des échanges textuels. ELIZA analyse un texte à la recherche de mots-clés pour générer des réponses adaptées.
Lorsqu’aucun mot-clé pertinent n’est détecté, le programme produit des réponses génériques. Ce qui imite un dialogue psychothérapeutique basé sur la méthode de Carl Rogers.
Le rôle d’ELIZA était de créer l’illusion d’une compréhension humaine, bien que le programme n’ait aucune réelle compréhension du contenu des échanges.
Ce stratagème permit à ELIZA de convaincre de nombreuses personnes qu’elles conversaient avec un véritable humain. C’est l’un des premiers programmes à « passer » une version primitive du Test de Turing.
Les risques liés aux chatbots modernes
Les chatbots modernes, descendants d’ELIZA et PARRY, continuent à évoluer et peuvent parfois tromper les humains de manière encore plus sophistiquée. Ces technologies sont désormais utilisées à des fins malveillantes dans certains cas.
Par exemple, le malware CyberLover utilise des tactiques d’ingénierie sociale pour convaincre les utilisateurs de divulguer des informations personnelles sensibles, souvent dans un contexte de séduction en ligne.
Ce type de programme montre comment les chatbots peuvent être exploités à des fins criminelles.
Le contre-argument de la chambre chinoise

Le contre-argument de la chambre chinoise, proposé par le philosophe John Searle en 1980, critique le Test de Turing comme une mesure valide de l’intelligence des machines.
Dans son article Minds, Brains, and Programs, Searle soutient que des programmes comme ELIZA ne « pensent » pas vraiment. Son argument repose sur l’analogie de la chambre chinoise.
En fait, une personne qui ne comprend pas le chinois peut suivre un ensemble de règles pour produire des réponses correctes, sans réellement comprendre le sens des symboles.
De même, une machine pourrait imiter une conversation humaine sans posséder une intelligence ou une compréhension réelle.
Cet argument a conduit à un débat philosophique sur la différence entre simuler l’intelligence et comprendre réellement.
Searle souligne que la manipulation de symboles ne suffit pas à prouver l’intelligence, et donc que les machines qui passent le Test de Turing ne font que simuler la pensée humaine.
Ce débat, qui touche à la nature de la conscience et de la cognition, reste central dans les discussions sur l’intelligence artificielle, particulièrement face aux avancées récentes dans ce domaine.
Le Prix Loebner, grande compétition des chatbots

Le Prix Loebner, créé en 1991 par Hugh Loebner, est une compétition annuelle d’intelligence artificielle. Son objectif est de mesurer la capacité des chatbots à réussir une version du Test de Turing.
Cette compétition a joué un rôle important dans le développement de l’IA conversationnelle. Toutefois elle a aussi soulevé des critiques sur la validité du Test de Turing, qui favorise l’imitation humaine plutôt que l’intelligence réelle.
Les premières éditions et critiques
De 1991 à 2003, la compétition a été organisée par le Cambridge Center for Behavioral Studies.
Les premières éditions ont vu des chatbots tromper des interrogateurs humains. Elles imitent des comportements humains comme les fautes de frappe.
Cependant, cela a révélé les limites du Test de Turing. Certains critiques affirment qu’il encourage la simulation plutôt que l’intelligence véritable.
Les victoires marquantes
Des programmes comme A.L.I.C.E. (Artificial Linguistic Internet Computer Entity) et Jabberwacky ont remporté plusieurs fois la médaille de bronze.
Cependant, les médailles d’argent et d’or, basées sur des interactions plus complexes, n’ont jamais été décernées.
En 2014, pour célébrer les 60 ans de la mort d’Alan Turing, le chatbot russe Eugene Goostman a marqué l’histoire en convainquant 33% des juges qu’il était humain lors d’une compétition à la Royal Society London.
Bien que cette victoire ait été saluée, elle a aussi été critiquée pour la durée limitée des conversations et la présentation particulière du chatbot.
Le test de Turing vise à répondre à une question philosophique profonde

La question de savoir si une machine est capable de penser tourmente les philosophes depuis des centaines, voire des milliers d’années, se posait déjà de façon sous-jacente avant même l’invention de la robotique.
Cette question est au cœur de la distinction entre le dualisme et le matérialisme de l’esprit humain?
Effectivement, dès 1637, dans le Discours de la Méthode, René Descartes s’interroge sur des problématiques similaires.
Le philosophe pointe du doigt la capacité des automates à réagir aux interactions humaines, mais souligne également leur incapacité à répondre aux paroles prononcées en leur présence de la même manière qu’un humain.
En fait, c’est pour lui la principale différence entre l’Homme et la machine. Cependant, Descartes ignorait que les automates du futur dépasseraient cette barrière. De fait, il se contente de préfigurer le cadre conceptuel du Test de Turing.
Dans Pensées philosophiques, Denis Diderot quant à lui évoque les mêmes critères d’intelligence que le test de Turing.
Il affirme que si un perroquet est capable de répondre à toutes les questions, ce volatile pourra sans hésitation être considéré comme intelligent.
La capacité à converser était donc déjà considérée comme une preuve d’intelligence par les matérialistes.
Selon les dualistes, l’esprit n’est pas physique et ne peut donc pas être expliqué en termes purement physiques.
Pour les matérialistes, l’esprit peut être expliqué physiquement, et il est donc possible de produire des esprits de manière artificielle.
En 1936, le philosophe Alfred Ayer s’est demandé comment peut-on savoir que les autres humains ont la même conscience que soi-même.
Dans son livre Language, Truth and Logic, Ayer suggère un protocole pour distinguer un humain conscient d’une machine inconsciente.
Selon lui, la seule façon de procéder est d’utiliser un test empirique pour déterminer la présence ou l’absence de conscience.
Forces et faiblesses du Test de Turing
Les forces du Test de Turing

L’une des principales forces du Test de Turing réside dans sa simplicité. Depuis des siècles, les philosophes, scientifiques et psychologues n’ont jamais réussi à définir précisément ce qu’est l’intelligence ou la pensée.
Ce test, malgré ses limitations, a au moins l’avantage de proposé un cadre pragmatique pour mesurer l’intelligence artificielle qui se base sur une interaction textuelle humaine.
Un autre atout est que le Test de Turing permet d’évaluer différentes compétences d’une IA, comme la maîtrise du langage naturel, la capacité de raisonnement, ainsi que l’apprentissage.
Le test s’appuie sur la conversation et ne se concentre pas uniquement sur des tâches techniques ou des calculs complexes.
Il évalue la manière dont l’IA interagit émotionnellement et socialement, ce qui reflète la complexité des échanges humains.
De plus, ce test peut être adapté pour intégrer des technologies plus récentes, telles que la vision par ordinateur et d’autres formes d’interactions multimodales (texte, vidéo, audio).
Cela permet d’explorer des champs plus larges dans l’évaluation de l’intelligence des machines, au-delà de la simple imitation linguistique..
Les faiblesses du test de Turing
Cependant, le Test de Turing a été critiqué à plusieurs reprises. L’une des principales critiques est qu’il n’évalue pas directement l’intelligence réelle d’une machine, mais uniquement sa capacité à simuler un comportement humain.
Le fait qu’une IA puisse tromper un interlocuteur ne signifie pas nécessairement qu’elle comprend ce qu’elle dit.
Par exemple, un programme pourrait imiter des comportements humains sans véritablement « penser », ce qui constitue un écart significatif entre la simulation d’une intelligence et l’intelligence elle-même.
Le jugement des interrogateurs est également remis en cause, car la qualité des interactions peut varier selon l’expertise ou les attentes de l’interrogateur.
Des chatbots primitifs comme ELIZA ont montré que des réponses simples, mais convaincantes, peuvent souvent tromper des humains naïfs.
En outre, le test est limité par le fait qu’il valorise la simulation humaine plutôt que la démonstration de capacités supérieures ou non humaines.
Par exemple, une machine capable de résoudre des problèmes complexes pourrait échouer au test si ses réponses sont jugées trop « non humaines », malgré sa supériorité en matière de traitement de l’information.
Cela a conduit à la proposition d’alternatives pour évaluer la « super-intelligence », au lieu de se concentrer uniquement sur la simulation humaine.
Test de Turing évalue uniquement la façon dont la machine se comporte
Le Test de Turing se concentre sur la capacité d’une machine à simuler un comportement humain au cours d’une conversation textuelle, sans nécessairement comprendre la conversation elle-même.
Comme l’a montré le programme ELIZA dans les années 1960, une machine peut passer le test en fournissant des réponses cohérentes, mais sans véritable compréhension.
Cette simulation de l’intelligence est ce que John Searle critique dans son célèbre argument de la chambre chinoise, affirmant que le test ne vérifie pas si une machine pense réellement, mais uniquement si elle semble penser.
Turing, cependant, estimait que la question de savoir si une machine peut penser importe moins que sa capacité à se comporter comme si elle pensait.
Pour lui, si une machine peut imiter un comportement humain au point de tromper un interlocuteur, elle mérite d’être considérée comme intelligente, au moins à un certain niveau.
Il voyait cela comme un premier pas dans l’exploration de la conscience machine, même si cela ne permet pas d’en élucider tous les mystères..
Un autre problème souligné par Michael Shermer est celui de l’anthropomorphisme. Les humains ont tendance à attribuer des caractéristiques humaines à des objets inanimés ou non humains.
Cela peut fausser le jugement lors de tests comme celui de Turing, où les interrogateurs interprètent certains comportements robotiques comme étant humains.
Paradoxalement, il arrive également que des interrogateurs prennent les humains pour des machines, ce qui illustre les difficultés du test à évaluer correctement l’intelligence.
Test de Turing : les utilisations actuellement
Le Test de Turing, bien qu’ayant évolué avec le temps, reste un outil de référence dans l’évaluation de l’intelligence artificielle. Voici quelques-unes des principales applications et exemples récents.

Le Prix Loebner : une version moderne du Test de Turing
Depuis 1991, le Prix Loebner est une compétition annuelle qui récompense les chatbots capables de démontrer un comportement conversationnel proche de celui des humains.
Ce concours, basé sur une version simplifiée du Test de Turing, a permis de faire progresser la recherche dans le domaine de l’IA conversationnelle.
Cependant, aucun chatbot n’a encore remporté la médaille d’argent ou d’or, qui nécessitent une imitation plus complète des capacités humaines.
Eugene Goostman et les controverses du test
En 2014, le chatbot russe Eugene Goostman a fait les gros titres. Il a réussi à tromper 33 % des juges lors d’une compétition organisée à la Reading University, les convainquant qu’il était humain.
Malgré cette performance, la victoire reste controversée. En fait, le test a duré seulement 5 minutes, et Eugene incarnait un adolescent de 13 ans, ce qui a pu excuser certaines incohérences dans ses réponses.
Google Duplex : une réussite moderne
En 2018, le service Google Duplex a marqué une étape majeure en IA. Capable de passer des appels téléphoniques pour réserver des rendez-vous, Duplex a bluffé un coiffeur qui ne se doutait pas qu’il parlait à une machine.
Cet exploit a été salué comme une nouvelle avancée dans le domaine de l’IA, même si cette interaction ne correspondait pas exactement au format du Test de Turing original.
GPT-4 et les avancées récentes en IA
L’année dernière, OpenAI n’a pas seulement évoqué, mais déjà consolidé le rôle de GPT‑4o comme modèle par défaut dans ChatGPT.
De plus, GPT‑4o a reçu plusieurs mises à jour depuis. Par exemple, le 27 mars 2025, OpenAI a annoncé qu’il serait plus intuitif, plus créatif, avec des capacités de codage renforcées et de meilleures instructions.
Il y a aussi une version plus légère, GPT‑4o mini , qui cherche à rendre l’IA plus accessible et économique, tout en conservant des capacités multimodales.
Cependant, malgré ces progrès, des limites subsistent. Les questions ambiguës ou paradoxales peuvent encore générer des réponses incorrectes ou incohérentes.
De plus, bien qu’il affiche une meilleure gestion des contextes prolongés, il reste dépendant de ses données d’entraînement et ne dispose pas d’une véritable compréhension humaine.
Ces défis soulignent que, bien qu’il s’en rapproche, GPT-4 ne parvient pas encore à satisfaire pleinement les exigences du Test de Turing
Avec l’arrivée de GPT-4.5, l’intelligence artificielle franchit un cap historique. Ce nouveau modèle a impressionné la communauté scientifique en réussissant un véritable test de Turing, convainquant 73 % des évaluateurs humains de sa nature humaine.
Ce score dépasse largement celui de ses prédécesseurs, faisant de GPT-4.5 une référence incontournable dans le domaine des IA génératives.
Cette performance n’est pas un cas isolé. Elle intervient peu de temps après le retrait de GPT-4, officiellement désactivé le 30 avril 2025 dans l’écosystème ChatGPT.
OpenAI a alors lancé GPT-4o, un modèle multimodal capable de traiter texte, image et son de manière fluide.
Ce modèle tout-en-un pousse encore plus loin les limites du test de Turing en simulant des échanges quasi-humains dans des environnements complexes.

Le Test de Turing en 2026 : pour une validation post-imitation ?
L’année 2025 s’achève sur un constat sans appel pour les chercheurs en intelligence artificielle.
Effectivement, le Test de Turing ne constitue plus un obstacle insurmontable pour les modèles de langage modernes.
Avec les performances records de GPT-4.5, la machine a prouvé sa capacité à simuler parfaitement l’humanité.
Aujourd’hui, les experts considèrent cette réussite comme une simple prouesse de calcul statistique. Les protocoles d’évaluation basculent donc vers des mesures de raisonnement logique pur pour 2026.
L’enjeu actuel consiste ainsi à détecter une véritable étincelle de compréhension derrière la fluidité du verbe.
Par conséquent, les nouveaux benchmarks privilégient la résolution de problèmes inédits sans données d’entraînement préalables.
Cette transition marque la fin de l’ère de l’imitation simple initiée par Alan Turing. Nous entrons dans une phase où l’autonomie décisionnelle devient le seul critère de distinction.
Ainsi, les dresseurs d’algorithmes cherchent maintenant à définir une intelligence qui ne se contente plus de nous ressembler.
Cette mutation technologique profonde redessine les frontières entre la conscience humaine et le traitement de l’information.
CAPTCHA : Un test de Turing inversé

Le CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) est une version inversée du Test de Turing.
Il permet de distinguer les humains des machines en demandant aux utilisateurs de résoudre des tâches simples, comme identifier des lettres déformées ou des images spécifiques.
Depuis l’avènement de l’apprentissage automatique, de nouvelles variantes de CAPTCHA, comme le reCAPTCHA, se concentrent sur des tâches plus complexes pour contrer les robots sophistiqués.
Les IA modernes face au Test de Turing
Les IA modernes, telles que GPT-4 d’OpenAI et LaMDA de Google, repoussent les limites de l’intelligence artificielle en matière de compréhension du langage naturel et d’interaction conversationnelle.
Ces modèles avancés peuvent générer des réponses crédibles et cohérentes dans divers contextes. Cela simule ainsi des conversations proches de celles d’un humain.
Cependant, malgré leurs prouesses, ces IA rencontrent encore des difficultés à passer entièrement le Test de Turing.
L’un des principaux défis réside dans leur manque de compréhension réelle. Bien que ces systèmes puissent donner des réponses convaincantes, ils ne « comprennent » pas véritablement le sens des mots qu’ils utilisent.
Leur apprentissage repose sur des algorithmes qui analysent et reproduisent des modèles linguistiques, ce qui les rend vulnérables à des erreurs lorsqu’ils sont confrontés à des contextes complexes ou ambiguës.
En outre, les IA modernes peinent à simuler des réactions émotionnelles authentiques et à interpréter les nuances sociales. Ce sont deux aspects essentiels pour tromper un interlocuteur humain de manière convaincante.
Les limites émotionnelles et contextuelles des IA trahissent souvent leur véritable nature de machines lorsqu’elles sont confrontées à des questions inattendues ou à des situations nouvelles.
Bien qu’elles soient capables de tenir des conversations avancées, ces IA sont encore loin de passer complètement le Test de Turing, qui nécessite une imitation plus subtile et humaine de la pensée et des émotions.
Au-delà du Test de Turing : comparaison des approches d’évaluation de l’IA
Outre le Test de Turing, plusieurs approches d’évaluation de l’IA ont émergé afin de mesurer plus précisément ses performances et ses capacités.
Parmi celles-ci, il y a notamment la reconnaissance d’images ou le traitement du langage naturel.
Ce sont des méthodes d’évaluation par des tâches spécifiques qui permettent de tester l’IA sur des compétences précises. Ces tests sont souvent quantitatifs et garentie des métriques claires et mesurables.

En revanche, il y a aussi des méthodes dites qualitatives, comme les évaluations par des experts. Ces derniers apportent des perspectives nuancées sur l’efficacité et la pertinence des réponses fournies par l’IA.
A cela s’ajoutent des approches récentes, telles que la mesure de l’alignement des valeurs. Celles-ci s’intéressent spécifiquement à la capacité de l’IA à agir en accord avec des principes éthiques et des normes sociales.
Ces différentes méthodes d’évaluation révèlent la complexité croissante des systèmes d’IA modernes.
Nous assistons en en realité à des systèmes complexes qui ne se limitent pas à l’imitation, mais engendrent également des défis en matière de responsabilité et d’interprétabilité.
Par conséquent, développer une approche multidimensionnelle pour évaluer l’IA s’avère indispensable.
Test de Turing et les progrès en intelligence artificielle
Proposé par le mathématicien britannique Alan Turing en 1950, le test de turing vise à déterminer si une machine pouvait être perçue comme intelligente par un interlocuteur humain.
Pour réussir ce test, une machine doit pouvoir converser de manière indistinguable d’un être humain. En 2026, certaines intelligences artificielles actuelles atteignent ce niveau de sophistication.
Les progrès en matière d’intelligence artificielle est considérable en 2026.
De ce fait, l’augmentation de la puissance de calcul et l’amélioration des algorithmes d’apprentissage automatique permettent aux machines d’analyser et d’interpréter des données complexes avec une précision sans précédent.
Ces avancées technologiques donnent aux systèmes d’IA la capacité de s’adapter et de s’améliorer sans intervention humaine directe.
De plus, l’atteinte de cette étape cruciale dans le développement de l’IA soulève des questions importantes sur son rôle futur dans la société.
L’apprentissage autonome des machines peut transformer de nombreux secteurs, de la santé à l’éducation ou encore la finance et le divertissement.
Ces progrès posent néanmoins des défis éthiques et de régulation, notamment en ce qui concerne la protection de la vie privée et la sécurité des données en 2025.

Test de Turing 2.0 : de nouveaux critères pour mesurer l’AGI
Face aux limites du Test de Turing classique, nous constatons que de nombreux chercheurs et experts en intelligence artificielle appellent aujourd’hui à une refonte des critères d’évaluation.
Parmi eux, Andrew Ng, figure majeure de l’IA moderne, souligne la nécessité, selon nous, de dépasser les tests fondés uniquement sur l’illusion conversationnelle.
Il propose une approche parfois qualifiée de « Turing-AGI », non pas comme un test unique et formel, mais comme un cadre conceptuel que nous jugeons plus pertinent pour évaluer l’intelligence artificielle générale (AGI).
Dans cette perspective, nous estimons qu’une IA ne devrait pas être évaluée uniquement sur sa capacité à se faire passer pour humaine.
Nous devrions considérer des critères concrets : résolution de problèmes inédits, capacité d’apprentissage autonome, adaptation à des contextes variés et compréhension réelle des objectifs.
Cette approche remet en question l’usage traditionnel du Test de Turing, que nous considérons aujourd’hui comme trop vague et potentiellement trompeur, à l’ère des grands modèles de langage capables de produire des réponses convaincantes sans compréhension profonde.
Le succès linguistique masque une lacune cognitive
L’année 2026 marque un tournant brutal dans l’évaluation de l’intelligence artificielle. Si des modèles comme GPT-5.2 ou Gemini 3 Pro réussissent désormais le Test de Turing avec une aisance déconcertante, ils se heurtent à un mur invisible : le benchmark ARC-AGI 2. Ce test, contrairement au protocole d’Alan Turing qui repose sur la fluidité du verbe, mesure la logique abstraite inédite.
L’épreuve de vérité face aux patterns inconnus
Le constat en ce mois de février 2026 est sans appel. L’ARC-AGI 2 demande à l’IA de résoudre des puzzles visuels qu’elle n’a jamais rencontrés dans ses données d’entraînement. Alors que les humains résolvent ces tâches avec une facilité déconcertante (plus de 60% de réussite en moyenne), les modèles de raisonnement les plus avancés, comme OpenAI o3, affichent des scores encore très faibles (environ 4% en autonomie pure).
Vers une distinction entre imitation et intelligence fluide
Cet échec retentissant prouve une chose essentielle : réussir le Test de Turing ne signifie pas « penser ». Une IA peut imiter l’humain par une intelligence cristallisée (mémorisation massive de patterns linguistiques) sans posséder d’intelligence fluide (capacité à improviser face à l’inconnu). Pour les chercheurs, l’ARC-AGI 2 est devenu le véritable filtre permettant de distinguer l’imitation statistique de la véritable Intelligence Artificielle Générale (AGI).
Alternatives modernes au Test de Turing
Actuellement, de nombreux chercheurs estiment que le Test de Turing ne suffit plus pour mesurer l’intelligence artificielle.
Nous n’utilisons donc plus les IA modernes pour converser. Bien au-delà de cela, elles résolvent des problèmes complexes, analysent des images ou encore génèrent du contenu multimédia.
C’est pourquoi de nouvelles approches ont vu le jour. Parmi elles, nous avons le Winograd Schema Challenge. Celui-ci propose de tester la compréhension contextuelle d’une machine à travers des phrases ambiguës.
D’autres méthodes, comme les évaluations multimodales, analysent la capacité d’une IA à combiner texte, son et image.
Nous retrouvons aussi des tests centrés sur l’éthique et l’alignement des valeurs. Ces derniers sont indispensables pour encadrer l’usage des chatbots et de l’IA générative.

FAQ – Test de Turing - mai 2026
Oui, mais son rôle évolue. Il reste un repère historique, mais les chercheurs explorent désormais des tests plus adaptés aux IA modernes, comme le Turing Test 2.0.
En mars 2025, GPT-4.5 a convaincu 73 % des évaluateurs qu’il était humain lors d’un test rigoureux, surpassant même les participants humains.
Il évalue la capacité à simuler un comportement humain, pas l’intelligence intrinsèque. D’autres tests sont nécessaires pour mesurer la compréhension réelle.
Non. Passer le test signifie imiter le langage humain, pas comprendre ou ressentir. C’est une simulation, pas une preuve de conscience.
L’industrie bascule vers la mesure de l’autonomie décisionnelle et de l’éthique. L’objectif n’est plus de ressembler à l’humain, mais de résoudre des problèmes sans aucune donnée pré-enregistrée.
- Partager l'article :

