
Meta vient de présenter V-JEPA, son nouveau modèle d’IA qui révolutionne l’entraînement des intelligences artificielles. Sa particularité ? Il est capable d’interpréter les informations contenues dans une vidéo et d’apprendre à la manière des humains.
Un modèle d’IA non génératif, se focalisant sur des concepts abstraits
V-JEPA, a été développé par Yann LeCun, scientifique en chef du laboratoire d’IA de Meta. Contrairement aux LLM habituels, il ne s’agit pas d’un modèle d’IA générative. V-JEPA apprend différemment des autres IA.
Au lieu de se concentrer sur la précision pixel par pixel pour générer de nouvelles images réalistes, il utilise plutôt des concepts abstraits pour apprendre. Il essaie donc de comprendre ce qui se passe dans la vidéo : la présence d’objets spécifiques (arbres, personnes, animaux) et les relations entre eux.
Cette façon d’apprendre ressemble au mode d’apprentissage des enfants. Ils observent ce qui se passe autour d’eux et essaient de donner un sens à ce qu’ils voient.
Un mode d’apprentissage plus naturel
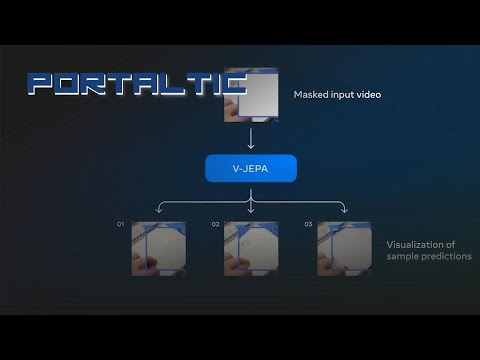
Pendant l’entraînement de V-JEPA, les chercheurs cachent plusieurs grandes parties des vidéos. Le modèle doit alors deviner ce qui manque. Ce faisant, il apprend à faire des inférences logiques sur le déroulement des événements.
Ce mode d’apprentissage est également semblable à celui des humains. C’est un peu comme un enfant qui observe une personne partir pour récupérer une balle. Elle disparait de son champ de vision. Ensuite, elle revient. L’enfant ne voit pas chaque étape de l’action. Cependant, en utilisant sa capacité d’observation et de raisonnement, il comprend la logique de la séquence d’événements.
Une amélioration de l’efficacité de l’entraînement
Cette approche novatrice adoptée par V-JEPA s’avère très prometteuse. D’après les chercheurs à l’origine du projet, elle permet d’accélérer considérablement l’entraînement de l’intelligence artificielle, le rendant 1,5 à 6 fois plus efficace. De plus, V-JEPA peut apprendre à partir de données vidéo non étiquetées. Il n’est pas nécessaire de préciser au préalable quels objets ou actions sont présents à l’écran.
Par ailleurs, ce modèle de Meta arrive à distinguer des interactions subtiles entre différents objets. Il peut par exemple identifier des actions très proches comme ramasser, poser ou faire semblant de poser un stylo. Toutefois, pour l’instant, V-JEPA ne performe que sur des courtes séquences, d’environ une dizaine de secondes. Mais, il est certain que ses performances s’amélioreront avec le temps.
Vers des IA plus intelligentes et autonomes
V-JEPA se limite actuellement à l’analyse visuelle des vidéos, mais les chercheurs de Meta travaillent à lui faire prendre en compte le contenu audio également. Selon eux, V-JEPA représente un pas important vers l’intelligence artificielle incarnée grâce à sa capacité à comprendre intuitivement la scène, sans avoir besoin d’instructions détaillées. Cette approche de l’IA vise à créer des agents dotés de capacités perceptives leur permettant d’interagir avec le monde réel.
Ainsi, on peut espérer la création d’assistants virtuels ou des robots dopés par l’IA bien plus intelligents et autonomes. Ils seront capables de comprendre leur environnement et d’y réagir comme le ferait un être humain.
- Partager l'article :
Restez à la pointe de l'information avec
INTELLIGENCE-ARTIFICIELLE.COM !








