
La classification d’image est une étape fondamentale de la vision par ordinateur, car c’est elle qui permet de décrire ce que contient une image. Actuellement, l’analyse des données visuelles constitue une part importante de la data analysis.
Les récentes avancées technologiques, et notamment en intelligence artificielle, ont impacté plusieurs aspects de notre quotidien. Les appareils intelligents nous facilitent la vie, comme les dispositifs médicaux qui accélèrent le diagnostic de certaines maladies. Mais derrière ces progrès révolutionnaires se tiennent des processus souvent complexes. Aujourd’hui nous allons aborder l’un d’entre eux : la classification d’image.
Qu’est-ce que la classification d’image ?
Par définition, la classification d’image consiste à étiqueter les éléments constitutifs d’une image suivant une règle prédéfinie. Elle implique l’utilisation d’un algorithme qui attribue les étiquettes aux groupes de pixels ou aux vecteurs. La classification d’images est un processus de la vision par ordinateur, et notamment l’étape la plus importante de cette technologie.
Mais avant d’aller plus loin, précisons d’abord de quelles images il s’agit. L’intelligence artificielle et l’IoT sont des technologies que de plus en plus de monde adopte. Alors que celles-ci se basent avant tout sur les données, elles en génèrent également une quantité énorme. C’est d’ailleurs cette explosion de données qui a donné naissance au Big Data.
Maintenant, les images (photos ou vidéos) constituent une grande partie de ces mégadonnées. La vision par ordinateur consiste à traiter ces images par un système d’IA pour en tirer parti. Et la classification d’image est la première étape dans ce processus.
En quoi est-ce important ?
Dans tout système d’intelligence artificielle, chaque décision prise ou chaque action effectuée est le résultat d’un long processus de traitement de données. Cependant, cela ne serait pas possible sans une parfaite compréhension des données.
En ce qui concerne la vision par ordinateur, cette compréhension commence avant tout par l’étiquetage des composants de l’image, autrement dit, la classification d’image.

Les différents types de classification d’image
Pour attribuer des étiquettes aux éléments d’une image, il existe plusieurs algorithmes. Mais d’une manière générale, ils peuvent être catégorisés en deux types d’approches :
La classification non supervisée
Dans la classification d‘image supervisée, les algorithmes de machine learning utilisés ne sont pas préentraînés. Autrement dit, ils apprennent par eux-mêmes à analyser et à regrouper les données brutes. Un algorithme extrait des caractéristiques en fonction desquelles les étiquettes seront attribuées.
Il existe deux algorithmes particulièrement connus pour la classification non supervisée qui sont « K-means » et « ISODATA ». K-means est une méthode clustering qui regroupe les pixels ou les vecteurs en K-groupes suivant les caractéristiques. Pour sa part, ISODATA se base sur la distance euclidienne pour mesurer la similarité entre les données.

La classification supervisée
Pour la classification d’image supervisée, les algorithmes sont donc pré-entraînés sur un ensemble d’images déjà étiquetées. Comme avec la classification non supervisée, l’algorithme extrait des caractéristiques à partir de la nouvelle image. Ensuite, il les compare à une liste de caractéristiques présélectionnées pour attribuer des étiquettes en fonction de celles-ci.
CNN et ViT : Les architectures clés de la classification profonde
La révolution de la classification d’image dépend des réseaux neuronaux profonds ou DNN.
Historiquement, le CNN s’est imposé comme la référence. Ce type d’architecture excelle à extraire des caractéristiques locales des pixels. Il a permis de franchir des étapes majeures en précision. Cependant, la recherche avance très vite.
Aujourd’hui, le Modèle Transformer transforme également la vision par ordinateur. Inspirés par les LLM, ces modèles traitent les images comme une séquence de patchs. Ils capturent ainsi des dépendances globales complexes.
Par conséquent, les Vision Transformers ou ViT surpassent souvent les CNN sur des jeux de données massifs. Leur puissance de calcul demande plus de ressources, mais elle ouvre de nouvelles perspectives.
Finalement, il est devenu plus qu’indispensable de maîtriser ces architectures. Cela permet aux développeurs de choisir la méthode la plus efficace pour chaque cas d’application.
Comment fonctionne la classification d’image ?
Du point de vue d’un ordinateur, une image correspond à un ensemble de pixels constituant un tableau de matrices. En d’autres termes, l’algorithme analyse ces éléments en tant que données statistiques. La classification d’image correspond donc au regroupement des pixels dans des classes spécifiques.
Comme nous l’avons vu précédemment, les algorithmes extraient des caractéristiques pour classer les images. Cette étape est primordiale pour la suite du processus. En effet, elle permet de définir ce que représente l’image et de séparer les éléments marquants afin de simplifier la tâche du classificateur final.

En outre, les données qui alimentent l’algorithme d’apprentissage automatique constituent également une base importante de la classification d’image. Une classification efficace repose avant tout sur des données bien équilibrées ainsi que des images et des annotations de qualité.
Attribuer les étiquettes
Après la collecte des données et l’extraction des caractéristiques, la prochaine étape de classification d’image est donc l’étiquetage. Afin que les algorithmes de classification puissent effectuer correctement leurs tâches, les étiquettes doivent être précises.
Une des conditions pour obtenir cette précision est la diversification des données. Les données diversifiéespeuvent par exemple correspondre aux différents angles de captures de l’élément à classifier.
Cela permet d’améliorer la précision de l’algorithme surtout dans le cas d’une classification non supervisée. Autrement dit, les données diversifiées renforcent les facteurs qui déterminent la prédiction des caractéristiques et donc de la classification.

Votre modèle peut échouer dans la classification d’images. Voici pourquoi
Si choisir la bonne architecture (CNN ou ViT) est crucial, je vais être franc avec vous : ce n’est que la partie émergée de l’iceberg.
Dans la réalité du terrain, la classification d’images se heurte souvent à des obstacles invisibles qui peuvent rendre un projet totalement inopérant.
La qualité des données et la nécessité de la Data Augmentation
Le premier mur, et souvent le plus haut, concerne la fiabilité du dataset. On entend souvent l’expression « Garbage in, garbage out » (si les données d’entrée sont mauvaises, le résultat le sera aussi), et c’est particulièrement vrai ici.
Avoir des milliers d’images ne suffit pas si elles sont mal étiquetées ou trop uniformes. C’est là qu’intervient une technique indispensable : la Data Augmentation.
Concrètement, si vous manquez de photos, on va « tricher » intelligemment en modifiant les images existantes (rotations, zooms, changements de luminosité) pour forcer l’algorithme à reconnaître l’objet sous toutes ses coutures, et pas juste quand il est bien centré.
Le piège du surapprentissage (Overfitting)
Ensuite, il y a le risque classique du surapprentissage. Imaginez un étudiant qui apprend par cœur les réponses d’un examen sans comprendre le cours.
Il aura 20/20 à l’entraînement, mais échouera lamentablement face à une nouvelle question. Votre modèle de classification d’images peut faire exactement la même chose : il « mémorise » le bruit ou les détails insignifiants de vos données d’entraînement au lieu de comprendre les caractéristiques globales.
Résultat ? Il devient incapable de généraliser sur de nouvelles images.
Biais et effet « boîte noire » : le défi de l’interprétabilité
Enfin, n’oublions pas l’effet « boîte noire » et les biais algorithmiques. Pourquoi l’IA a-t-elle classé cette photo en « chat » et pas en « chien » ?
Parfois, l’algorithme se base sur des détails absurdes (comme la couleur du tapis en arrière-plan) sans que vous le sachiez.
C’est un défi éthique et technique majeur, surtout si votre système est utilisé dans des domaines sensibles comme la santé ou la sécurité.
Réussir sa classification d’images, c’est donc aussi savoir auditer son modèle pour s’assurer qu’il ne reproduit pas des préjugés cachés.

Classification d’images : faites le premier pas sans tracas
La classification d’images est devenue un outil incontournable dans de nombreux domaines, de la médecine à la sécurité, en passant par le marketing. Faire le premier pas dans ce domaine peut sembler intimidant, mais avec les bonnes ressources et une approche méthodique, cela devient un processus accessible et sans tracas.
Tout commence par la compréhension des concepts fondamentaux. Il est crucial de se familiariser avec les algorithmes d’apprentissage automatique. Commencez par vous adapter avec les réseaux de neurones convolutifs (CNN), qui sont particulièrement efficaces pour traiter des données visuelles.
Ensuite, il est important de rassembler une base de données d’images pertinentes, étiquetées de manière appropriée, afin d’entraîner votre modèle. Heureusement, plusieurs bibliothèques et outils, comme TensorFlow ou PyTorch, offrent des fonctionnalités prêtes à l’emploi pour faciliter cette étape.
Une fois votre modèle entraîné, il est temps de le tester et de l’affiner. N’oubliez pas que la classification d’images ne se limite pas à une simple tâche technique. Elle requiert également une compréhension des enjeux éthiques et des biais potentiels dans les données.

Découvrez les différents cas d’application de la classification d’images par l’IA en 2025
L’intelligence artificielle transforme radicalement l’imagerie médicale en 2025. Les technologies de classification d’images offrent des capacités médicales extraordinaires, notamment dans la détection précoce des maladies.
Les algorithmes analysent les rayons X, les IRM et les tomodensitogrammes avec une précision microscopique. Ils permettent aux médecins de détecter des anomalies avant qu’elles ne deviennent critiques.
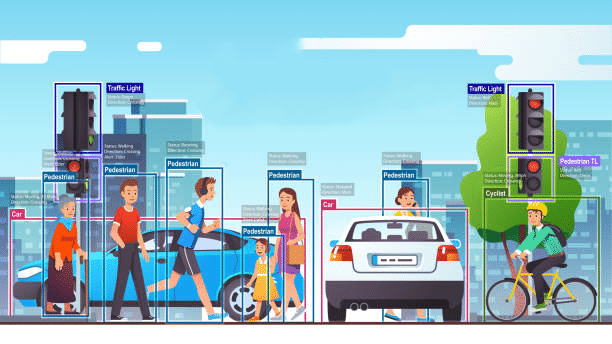
Dans le domaine des véhicules autonomes, la catégorisation d’images par IA joue un rôle crucial pour la sécurité routière. Les systèmes intelligents identifient instantanément les panneaux de signalisation, les piétons et les obstacles.
Les caméras embarquées surveillent en permanence l’environnement, réduisant les risques d’accidents et améliorant la navigation dans des conditions difficiles.
Le secteur du commerce de détail bénéficie également de ces avancées technologiques. Les solutions d’IA permettent une recherche visuelle précise des produits, une gestion automatisée des stocks et une analyse approfondie du comportement des consommateurs.
Les magasins peuvent désormais offrir des expériences d’achat personnalisées et optimiser leurs stratégies marketing.
En outre, la sécurité et la surveillance connaissent une révolution technologique en 2025. Les systèmes intelligents détectent les comportements suspects, améliorent les contrôles d’accès et renforcent la sécurité biométrique. Dans l’industrie manufacturière finalement, l’IA inspecte la qualité des produits avec une précision inégalée.
- Partager l'article :

