LangGraph s’est imposé comme le cadre de référence (framework) pour orchestrer ces nouveaux collaborateurs virtuels. En permettant la création de flux de travail cycliques et ramifiés tout en gérant automatiquement l’état et la mémoire, LangGraph transforme les modèles de langage en véritables moteurs de pilotage pour l’entreprise.
Ce dossier exhaustif décortique chaque brique technologique de ce paradigme et vous guide, étape par étape, dans le déploiement de votre premier agent autonome professionnel sur LangGraph.
LangGraph, l’infrastructure standard des agents IA
L’année 2025 a été celle de l’expérimentation, mais 2026 est celle de l’industrialisation des agents.
LangGraph se distingue des solutions linéaires par sa structure basée sur les graphes, offrant une souplesse indispensable pour les systèmes multi-agents robustes qui exigent une prise de décision en temps réel et une gestion sophistiquée des erreurs.
Dans ce cadre, chaque étape d’un processus est vue comme un nœud interconnecté, capable d’exécuter un modèle de langage (LLM), un outil ou une fonction personnalisée.
L’innovation majeure réside dans la capacité de LangGraph à maintenir un « État » (State) persistant, une mémoire partagée qui circule à travers le graphe pour stocker les variables, l’historique des décisions et les résultats intermédiaires.
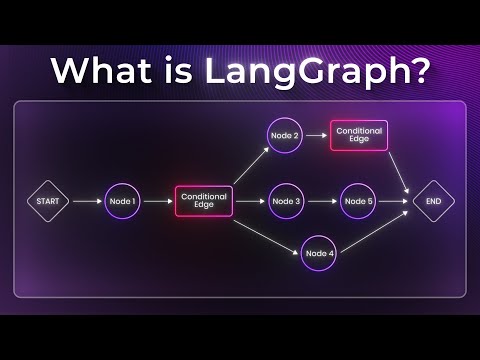
Principes fondamentaux : l’anatomie d’un graphe intelligent
Pour maîtriser LangGraph, il faut d’abord comprendre les éléments structurants qui permettent de construire des flux de travail évolutifs et dotés d’un état.
L’État (State) est l’objet central. On peut le comparer à une mémoire vive partagée par tous les composants du système. Il ne se contente pas de stocker des messages ; il permet la persistance entre les sessions et la gestion de threads locaux, rendant le développement plus efficace grâce à une automatisation complète de la gestion des données.
Les Nœuds (Nodes) sont les unités fonctionnelles du flux. Chaque nœud prend l’état actuel en entrée, effectue une action spécifique (comme appeler une API ou exécuter une fonction Python), et renvoie un état mis à jour. C’est ici que réside l’intelligence granulaire de l’agent.
Les Arêtes (Edges) définissent la circulation de l’information. On distingue les connexions statiques, pour une progression linéaire, des arêtes conditionnelles qui permettent des branchements dynamiques. Ces dernières sont essentielles pour créer des comportements itératifs ou cycliques, où l’agent peut décider de revenir en arrière pour corriger une erreur ou affiner une recherche.
Enfin, le StateGraph représente la fusion ultime entre l’état et la structure. C’est ce graphe spécialisé qui garantit une prise de décision contextuelle tout au long de l’exécution, transformant une suite d’instructions en une véritable structure de pensée.

La gestion des messages et des outils
Un agent autonome ne serait rien sans sa capacité à communiquer et à interagir avec le monde extérieur.
LangGraph utilise une typologie de messages très précise pour assurer la traçabilité et la contextualisation des décisions.
- Human Message : représente l’entrée directe de l’utilisateur, le point de départ de la conversation.
- AIMessage : encapsule les réponses générées par le LLM, servant de base à la mémoire conversationnelle.
- System Message : définit le comportement profond de l’agent (ex: « Vous êtes un expert en logistique »).
- Tool Message : contient la sortie d’un outil externe, crucial pour que l’IA puisse valider une étape avant de poursuivre.
- Supprimer le message : Permet d’annuler ou de corriger des informations obsolètes dans l’état.
Le concept de ToolNode constitue ici une révolution pour les développeurs. Il s’agit d’un type de nœud dédié à l’exécution d’outils, qu’ils soient intégrés (comme la recherche web préconfigurée par LangChain) ou personnalisés.
Pour créer un outil personnalisé, il suffit d’utiliser un décorateur et une « DocString » détaillée. Cette documentation textuelle est primordiale car elle fournit au LLM le contexte nécessaire pour comprendre quand et comment appeler l’outil de manière fiable.

Guide étape par étape pour coder son premier agent autonome
Le déploiement d’un agent LangGraph repose sur une logique de modularité totale. Il permet d’utiliser des modèles provenant de divers fournisseurs comme OpenAI, Anthropic ou Ollama grâce à la famille d’outils « Chat » de LangChain.
1. Préparation de l’environnement et Typage
Avant de commencer, nous utilisons TypedDict pour assurer une sécurité des types robuste, un prérequis essentiel pour le développement d’agents IA complexes. Voici un exemple de définition de type :
Python
from typing import TypedDict
class Student(TypedDict):
name: str
grade: float
s1: Student = {"name": "Sam", "grade": 92.5}2. Définition de l’état et du modèle de traitement
La création de l’état de l’agent (AgentState) définit comment les informations seront stockées. Ici, nous stockons les messages utilisateur sous forme de liste.
Python
load_dotenv() # Obtaining over secret keys
# Creation of the state using a Typed Dictionary
class AgentState(TypedDict):
messages: List[HumanMessage] # We are going to be storing Human Messages (the user input) as a list of messages
llm = ChatOpenAI(model="gpt-4o") # Our model choice
# This is an action - the underlying function of our node
def process(state: AgentState) -> AgentState:
response = llm.invoke(state["messages"])
print(f"\nAI: {response.content}")
return state
graph = StateGraph(AgentState) # Initialization of a Graph
graph.add_node("process_node", process) # Adding nodes
graph.add_edge(START, "process_node") # Adding edges
graph.add_edge("process_node", END)
agent = graph.compile() # Compiling the graph
3. Construction et compilation du Graphe
Une fois la logique définie, nous assemblons le graphe en reliant les nœuds par des arêtes.
Python
graph = StateGraph(AgentState) # Initialisation du graphe
graph.add_node("process_node", process) # Ajout du nœud de traitement
graph.add_edge(START, "process_node") # Arête du début vers le nœud
graph.add_edge("process_node", END) # Arête du nœud vers la fin
agent = graph.compile() # Compilation du graphe pour le rendre exécutable4. Exécution et visualisation
Le code suivant permet d’appeler l’agent plusieurs fois de manière interactive. Pour vérifier la cohérence du flux, LangGraph permet également de générer un diagramme Mermaid.
Python
user_input = input("Enter: ")
while user_input != "exit":
agent.invoke({"messages": [HumanMessage(content=user_input)]})
user_input = input("Enter: ")
# Visualisation du graphe compilé
from IPython.display import Image, display
display(Image(agent.get_graph().draw_mermaid_png()))Agents ReAct et outils personnalisés : raisonnement et action
Les agents ReAct (Reasoning and Acting) sont la norme de l’industrie pour leur robustesse. LangGraph dispose d’une méthode intégrée, create_react_agent, pour faciliter leur création.
Python
from langgraph.prebuilt import create_react_agent
from langchain_google_community import GmailToolkit
tools = [GmailToolkit()] # We are using the Inbuilt Gmail tool
llm = ChatOllama(model="qwen2.5:latest") # Leveraging Ollama Models
agent = create_react_agent(
model = llm, # Choice of the LLM
tools = tools, # Tools we want our LLM to have
name = "email_agent", # Name of our agent
prompt = "You are my AI assistant that has access to certain tools. Use the tools to help me with my tasks.", # System Prompt
)@tool
def send_email(email_address: str, email_content: str) -> str:
"""
Sends an email to a specified recipient with the given content.
Args:
email_address (str): The recipient's email address (e.g., '[email protected]')
email_content (str): The body of the email message to be sent
Returns:
str: A confirmation message indicating success or failure
Example:
>>> send_email('[email protected]', 'Hello John, just checking in!')
'Email successfully sent to [email protected]'
"""
# Tool Logic goes here
return "Done!"production-ready full-stack AI agent template you didn't know you needed
— Vaishnavi (@_vmlops) March 20, 2026
FastAPI + Next.js + pick your framework:
→ PydanticAI
→ LangChain / LangGraph
→ CrewAI / DeepAgents
WebSocket streaming, auth, multi-DB, 20+ integrations all out of the box
just run: pip install… pic.twitter.com/NWRnbrFpuH
Gestion avancée de la mémoire et persistance
La mémoire fournit le contexte nécessaire pour rendre un agent fiable. LangGraph propose plusieurs approches pour gérer l’historique et la persistance.
1. Fonctions réductrices (Reducers)
Pour les systèmes complexes, il est recommandé d’utiliser des « reducers » pour l’état. Ces annotations garantissent que chaque nouveau message est ajouté à la liste existante au lieu de la remplacer.
Python
# State with reducer function
class AgentState(TypedDict):
messages: Annotated[list[BaseMessage], operator.add]2. Persistance externe et Points de contrôle
La persistance permet de maintenir le contexte à travers différentes interactions. LangGraph supporte SQLite, PostgreSQL, Amazon S3 ou encore Google Cloud. SQLite est une option simple et efficace :
Python
from langgraph.checkpoint.sqlite import SqliteSaver
memory = SqliteSaver.from_conn_string(":memory:") # This is for connecting to the SQLite database
graph = graph_builder.compile(checkpointer=memory) # Compiling graph with checkpointer as SQLite backend3. Mémoire à court et long terme
La mémoire à court terme conserve l’historique d’une session (via un thread_id), tandis que la mémoire à long terme persiste au-delà des sessions pour se souvenir des objectifs ou des préférences de l’utilisateur.
Python
# Exemple de mémoire à court terme
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.graph import StateGraph
checkpointer = InMemorySaver()
builder = StateGraph(...)
graph = builder.compile(checkpointer=checkpointer)
# Invoking the Graph with our message
agent_graph.invoke(
{"messages": [{"role": "user", "content": "What's the weather today?"}]},
{"configurable": {"thread_id": "session_42"}},
)
# Exemple de mémoire à long terme
from langgraph.store.memory import InMemoryStore
from langgraph.graph import StateGraph
long_term_store = InMemoryStore()
builder = StateGraph(...)
agent = builder.compile(store=long_term_store)
Optimisation du contexte : élagage et synthèse
À mesure qu’une conversation s’allonge, il devient important de limiter l’historique pour ne pas saturer le modèle.
L’élagage (Trimming) permet de supprimer les messages les plus anciens :
Python
from langchain_core.messages.utils import trim_messages, count_tokens_approximately
trimmed = trim_messages(
messages=state["messages"],
strategy="first", # remove the messages from beginning
token_counter=count_tokens_approximately,
max_tokens=150
)L’élagage basé sur la synthèse est plus intelligent : un nœud utilise un LLM pour résumer la conversation passée, conservant ainsi les informations essentielles sans gaspiller de jetons.
Python
from langmem.short_term import SummarizationNode
from langchain_core.messages.utils import count_tokens_approximately
summary_node = SummarizationNode(
model=summary_llm, # Our summarization LLM
max_tokens=300, # Total token limit
max_tokens_before_summary=150, # when to start summarizing
max_summary_tokens=150, # summary size
token_counter=count_tokens_approximately
)Enfin, la suppression sélective permet de nettoyer l’état en retirant les messages redondants (comme les sorties d’outils déjà traitées) ou l’historique complet pour réinitialiser la conversation.
Python
from langchain_core.messages import RemoveMessage
def clean_state(state):
# Remove all tool-related messages
to_remove = [RemoveMessage(id=msg.id) for msg in state["messages"] if msg.role == "tool"]
return {"messages": to_remove}Comparatif : modèles d’architectures agentiques 2026
Le choix de la structure de votre agent déterminera son efficacité opérationnelle.
| Type d’Architecture | Mécanique de décision | Cas d’usage idéal |
| Agent Séquentiel | Exécution linéaire sans ramification. | Processus métier fixes (ex: validation de facture). |
| Agent ReAct | Itération entre raisonnement et appel d’outils. | Assistants polyvalents nécessitant des recherches web. |
| Multi-Agent (LangGraph) | Orchestration de plusieurs nœuds experts avec état partagé. | Systèmes complexes (ex: support client + diagnostic technique). |
Foire aux questions
Quelle est la différence entre un agent classique et un agent LangGraph ?
Un agent classique est souvent une boucle simple. LangGraph introduit la notion de graphe cyclique avec état persistant, permettant une gestion des erreurs et des retours en arrière impossible dans les systèmes linéaires.
Comment créer un outil personnalisé fiable ?
Il faut impérativement utiliser le décorateur @tool et une DocString extrêmement précise incluant des exemples. C’est cette documentation qui permet au LLM de comprendre l’intention derrière l’outil et de l’appeler avec les bons paramètres.
Pourquoi utiliser TypedDict pour l’état ?
Dans un environnement B2B, la sécurité des types est cruciale. TypedDict empêche les erreurs de structure de données lors des mises à jour continues entre les nœuds, garantissant la stabilité de l’agent à grande échelle.
Comment l’agent gère-t-il les conversations très longues ?
Grâce aux stratégies d’élagage et de synthèse. Le système peut soit couper les messages les plus anciens, soit demander à un LLM secondaire de résumer l’historique pour maintenir le contexte sans exploser le budget de tokens.
- Partager l'article :

