
Après DALL-E 2 d’OpenAI et Imagen de Google, c’est au tour de Make-A-Scene de Meta de faire son entrée dans le domaine de l’IA générative. Mais la nouvelle venue offre un peu plus, selon ses créateurs.
Grâce à l’intelligence artificielle, créer des œuvres d’art n’a jamais été aussi facile. En effet, à l’aide d’une simple description textuelle et de quelques clics, tout le monde peut donner forme à son imagination. Cette fois, c’est Meta qui lance son propre générateur d’art IA pour les artistes et non-artistes.
Make-A-Scene ou comment générer un art visuel avec l’IA de Meta
Parallèlement aux grands modèles de langages, les grandes entreprises d’IA font également la course dans le domaine de la generative AI. Pour rappel, il y a quelques mois, OpenAI a dévoilé DALL-E 2, la dernière version de son IA génératrice de texte en image. Quelques semaines plus tard, Google a lancé Imagen. En termes simples, ces IA permettent aux utilisateurs de générer des images à partir d’un texte.
La semaine dernière, Meta a dévoilé Make-A-Scene, en la présentant comme outil d’IA qui transforme les croquis et le texte en œuvres d’art. Selon Mark Zuckerberg, Make-A-Scene est conçu pour donner à tout le monde des capacités créatives. Cela inclut à la fois les artistes et ceux qui ne le sont pas.
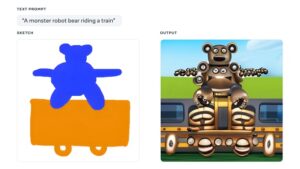
Plus que des mots
Dans le cas de DALL-E 2 et d’Imagen, l’IA s’appuie uniquement sur les invites textuelles pour générer des images. Pour sa part, NVIDIA propose CANVAS qui permet de transformer les croquis en images photoréalistes en quelques clics.
Selon Meta, les textes sont limités. De ce fait, il est souvent difficile de prédire les résultats que le générateur produira. Par exemple, les tailles des objets représentés ne sont pas toujours cohérentes avec les autres éléments de l’image.
Avec Make-A-Scena, Meta propose donc de transmettre la vision des utilisateurs d’une manière plus efficace. À cet effet, elle prend en compte plus de spécificité et une plus grande variété d’éléments, de formes, d’arrangements, de profondeurs, de compositions et de structures.
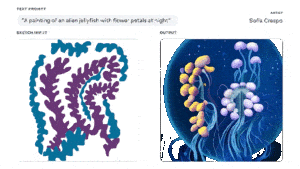
En d’autres termes, l’équipe a opté pour une approche multimodale afin d’avoir un meilleur contrôle sur la création. Les créateurs peuvent donc donner forme à leur imagination à l’aide d’une description textuelle, mais également de croquis de forme libre. Mais si les utilisateurs le souhaitent, ils peuvent toujours utiliser uniquement un texte ou un croquis.
Pour former le modèle, Meta note avoir utilisé des millions d’exemples d’images provenant de sources accessibles au grand public. Cela signifie que les résultats sont susceptibles de refléter les biais dans ces données. Mais l’équipe affirme travailler sur la compréhension et la résolution de ces défis pour améliorer son outil
Par ailleurs, le lancement de Make-A-Scene ne serait que le début et Meta espère bien sûr pouvoir appliquer ces récentes recherches au développement du metaverse.
- Partager l'article :

