
Gopher, le nouveau modèle de langage de DeepMind a été conçu pour tester les limites des grands systèmes linguistiques d’IA.
La génération de langage est un domaine très concurrentiel pour les grandes entreprises technologiques. Les chercheurs de DeepMind se sont alors demandé si la taille des modèles a un rôle à réellement un impact sur l’efficacité des modèles. Pour découvrir les limites des grands modèles de langages, ils en ont construit un avec 280 milliards de paramètres.
Gopher, le nouveau modèle de langage de DeepMind
En termes d’avancées en IA, les modèles de langages se développent de plus en plus. Cela rend les chatbots plus personnalisables ou la création de résumés plus cohérents. Même les développeurs de jeux vidéo ont réussi à tirer profit de la génération de texte par l’IA.
Pour les chercheurs de DeepMind, le développement d’un modèle de langage plus puissant permet de construire des systèmes d’IA plus avancés. Ainsi, ils ont construit un nouveau modèle baptisé Gopher qui contient 280 milliards de paramètres. C’est supérieur aux 175 milliards de paramètres du GPT-3 d’OpenAI mais bien loin des 530 milliards du MT-NLG de Microsoft et Nvidia.
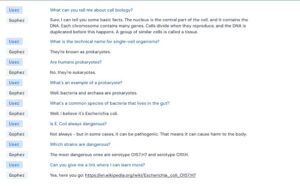
Cependant, une mise à l’échelle est nécessaire pour évaluer les limites et l’impact de ces grands modèles de langages. De ce fait, en plus de la présentation de Gopher, DeepMind a publié deux autres articles sur le sujet. L’un évalue les risques éthiques et sociaux liés à ces modèles tandis que l’autre étudie la création d’une nouvelle architecture plus efficace.
Une mise à l’échelle des grands modèles pour tester leurs limites
En créant son modèle de langage Gopher, DeepMind est parti du principe que les modèles plus complexes (données et puissance de calcul) sont plus performants. C’est effectivement le cas lorsqu’il s’agit de résoudre les problèmes tels que l’analyse de sentiments et la génération de résumés. Les chercheurs ont d’ailleurs évalué d’autres modèles sur 152 points de référence. Et d’après les résultats, les grands modèles de langages offrent effectivement de meilleurs résultats.
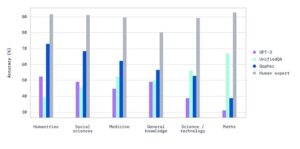
Toutefois, d’autres défis de la génération de texte par l’IA requièrent, selon eux, une solution qui va au-delà des données et des calculs. Cela inclut la production de résultats stéréotypés ou la génération de faux contenus. Dans ces cas de figure, DeepMind suggère l’adoption de routines de formations supplémentaires, notamment le retour d’informations des utilisateurs humains.
- Partager l'article :

