
Les résultats de classifications d’images par le deep learning se caractérisent parfois par la surinterprétation.
Pour ces systèmes, même des données qui n’ont pas de sens pourraient en avoir et c’est un véritable problème pour certains domaines. Dans plusieurs cas d’application, l’interprétation des données doit se faire en se basant sur le maximum d’informations possibles. Mais les modèles de deep learning ont tendance à chercher plus loin que ce qu’elles voient.
Le deep learning et la surinterprétation
Sans une IA explicable, il est difficile de comprendre le processus par lequel une machine est passée pour aboutir à une décision. Pour évaluer un système de classification d’images, les chercheurs se basent sur la précision du modèle.
Généralement, le taux de précision reste élevé même si les images manquent d’informations significatives. C’est cet aspect du deep learning que les chercheurs du MIT appellent la surinterprétation. En termes simples, le modèle prend une décision fiable en se basant sur peu d’informations, voire aucune.

Cependant, cette capacité de prédire des résultats à partir de rien n’est pas toujours une bonne chose. Par exemple, pour diagnostiquer des maladies, une prise de décision doit impérativement se baser sur des informations complètes. De même, dans un système de conduite autonome, le traitement des informations doit se faire en temps réel en toute connaissance de l’environnement.
Une stratégie d’atténuation
Pour tenter de résoudre ce problème de surinterprétation des approches de deep learning, les chercheurs du MIT ont mis au point une méthode appelée « Batched Gradient SIS ». Il s’agit, selon eux, d’une technique qui permet de découvrir des sous-ensembles d’entrées pour des ensembles de données complexes. Elle consiste à atténuer la surinterprétation par l’assemblage des modèles et par un dropout des entrées.
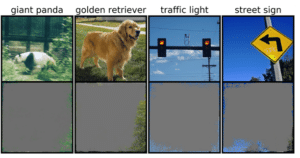
Ils ont constaté que l’assemblage permet d’améliorer la précision tout en augmentant la taille des SIS (sous-ensembles d’entrées suffisants). Quant à la technique de dropout, elle leur a permis de réaliser que constater une augmentation de 6 % du taux de précision, en conservant les pixels d’entrée avec une probabilité p = 0,8.
Toutefois, malgré ces résultats améliorés, l’atténuation de la surinterprétation ne remplace pas de meilleures données d’entraînement pour le modèle de deep learning. Autrement dit, la solution idéale reste jusqu’ici une des données soigneusement sélectionnées et informées.
- Partager l'article :

