Un auto-encodeur est un type d’algorithme d’apprentissage non supervisé utilisé pour régénérer la représentation d’un ensemble de données d’entrée. Il est constitué par des réseaux neuronaux et permet de résoudre nombreuses tâches.
La résolution de n’importe quelle tâche d’IA repose principalement sur l’apprentissage à partir du jeu de données. Il existe différents techniques et algorithmes d’apprentissage adaptés à chaque tâche. Aujourd’hui, nous vous invitons à découvrir ce qu’est un auto-encodeur ainsi que sa formation et son utilité.
Qu’est-ce qu’un auto-encodeur ?
En termes simples, un auto-encodeur est un type d’algorithme d’apprentissage non supervisé utilisé notamment dans le deep learning. Il est donc constitué d’un réseau neuronal profond permettant de construire une nouvelle représentation de données. Autrement dit, l’auto-encodeur permet de reconstruire une entrée à partir du code de données non étiquetées. Par conséquent, le nombre de neurones sur la couche de sortie doit être identique à celui de la couche d’entrée. L’algorithme vise à ce que la sortie soit la plus proche de l’entrée.
Un auto-encodeur s’entraîne à extraire les parties les plus importantes d’une entrée afin de générer une sortie qui présente moins de descripteurs. En d’autres termes, le réseau ignore le bruit, généralement pour réduire la dimensionnalité de l’entrée.

Comment ça fonctionne ?
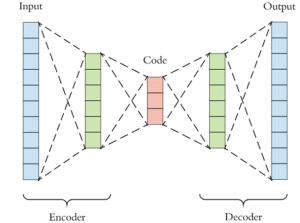
L’architecture d’un auto-encodeur se compose de deux ensembles de couches de neurones. Le premier ensemble forme ce qui est appelé l’encodeur qui traite les données d’entrées pour construire de nouvelles représentations (code). Le deuxième ensemble, dit décodeur, tente de reconstruire les données à partir de ce code.
De ce fait, la performance d’un auto-encodeur se mesure par les différences entre les données d’entrées et les données de sortie. Par ailleurs, pour entraîner l’algorithme, ses paramètres sont modifiés de manière à réduire l’erreur de reconstruction.
L’encodeur
Pour faire simple, l’encodeur sert à compresser le jeu de données d’entrée en une représentation plus petite. À cette fin, il extrait les caractéristiques (features) les plus importantes à partir de données initiales. Cela aboutit à une formation compacte appelée bottleneck aussi connu comme l’espace latent.
Le décodeur
À l’inverse de l’encodeur, le décodeur décompresse le bottleneck pour reconstituer les données. Son défi consiste à utiliser les caractéristiques contenues dans le vecteur condensé pour essayer de reconstruire le plus fidèlement possible le jeu de données.
L’espace latent
L’espace latent correspond donc aux données compressées, autrement dit à l’espace entre l’encodeur et le décodeur. Le but de la création de cet espace latent est de limiter le flux d’information entre les deux composants de l’auto-encodeur. Cette limitation se traduit par la suppression du bruit afin de ne laisser passer que les informations importantes.
Un bottleneck est donc soumis à un double défi. Le premier consiste à empêcher la mémorisation de l’entrée par le décodeur pour éviter la suradaptation. Le second défi est de fournir le maximum d’informations pour réduire le risque d’erreur de reconstruction.

Comment entraîner un auto-encodeur ?
L’entraînement de l’auto-encodeur vise donc à faire en sorte qu’il réussisse à décoder le code avec précision. La formation consiste à lui fournir des entrées qu’il doit encoder en un espace latent d’une dimension fixée. Une fonction de perte est fixée correspondant à l’écart entre les données d’entrées et celles de sorties. Celle-ci est appelée reconstruction loss et permet de suivre l’entraînement de l’algorithme.
Pour le reste, le processus d’entraînement est similaire à celui des architectures de réseaux neuronaux classiques, incluant notamment une fonction d’optimisation et un calibrage des paramètres.
Sur quoi repose l’entraînement d’un auto-encodeur ?
Le paramétrage d’un auto-encodeur repose avant tout sur la taille du code (espace latent).
Autrement dit, la compréhension des données est conditionnée par la quantité d’informations dans le bottleneck. Une bonne taille de code devrait donc permettre une reconstruction sans erreur. En revanche, une erreur de reconstruction peut se traduire par une taille insuffisante de l’espace latent.
En outre, le réglage de l’algorithme repose aussi sur le nombre de couches de neurones. Plus un réseau est profond, plus le modèle est complexe. Toutefois, un réseau moins profond est plus rapide à former.
De même, le nombre de nœuds par couche joue un rôle important dans le paramétrage d’un auto-encodeur. Il définit les poids utilisés par couche et diminue généralement à chaque couche suivante. En effet, l’entrée de chacune des couches s’allège d’une couche à une autre.
Le dernier paramètre est la reconstruction loss. Celle-ci dépend du type de données que l’auto-encodeur doit traiter. Pour la reconstruction de données d’image, les fonctions de perte les plus utilisées sont la perte MSE et la perte L1.
Quels sont les différents types d’auto-encodeurs ?
Il existe différents types d’auto-encodeurs, mais nous pouvons déjà citer les auto-encodeurs over-complete et les auto-encodeurs under-complete. Dans le cas d’un auto-encodeur over-complete, l’espace latent a une taille plus grande que les données d’entrée et de sortie. Un auto-encodeur under-complete désigne donc une architecture dont l’espace latent présente une réduction de dimension. Ce dernier est principalement utilisé pour générer un espace latent que le décodeur peut facilement décompresser si besoin.

Il peut être confondu avec l’analyse en composantes principales (ACP) qui utilise également la réduction de dimensionnalité. La différence réside dans le fait que l’auto-encodeur under-complet peut apprendre des relations non linéaires.
Par ailleurs, il n’a pas de terme de régularisation explicite. Cela signifie que le meilleur moyen d’empêcher la mémorisation des données est de limiter la taille de l’espace latent.
Les auto-encodeurs régularisés
Certes, même un seul nœud peut être efficace pour le codage under-complete si l’encodeur et le décodeur disposent suffisamment de capacités. Néanmoins, l’apprentissage et le nombre d’informations à capturer restent importants. Par conséquent, les divers techniques de régularisation permettent de limiter la mémorisation de l’identité et de privilégier les informations importantes.
Auto-encodeur épars
Le résultat attendu d’un auto-encodeur épars est la reconstruction du même jeu de données d’entrée. La régularisation consiste alors à changer le nombre de nœuds dans la couche cachée (espace latent). Pour ce faire, l’auto-encodeur pénalise l’activation de certains neurones avec une fonction de perte dite parcimonie. En d’autres termes, au lieu de créer une pénalisation sur la taille des poids aux nœuds, la parcimonie pénalise le nombre de nœuds activés.
Auto-encodeur débruiteur
Comme son nom l’indique, un auto-encodeur débruiteur supprime le bruit d’une image. Dans ce cas-là, l’image de sortie n’est pas identique à l’image d’entrée. En effet, pour entraîner ce type de réseau, il faut lui fournir une version bruyante de l’image en ajoutant des altérations numériques. Les données d’entrées sont donc corrompues et l’encodage débruiteur consiste à reconstruire les données non déformées. Concernant l’espace latent, le réseau procède à une réduction non linéaire de la dimensionnalité, généralement par une loss function L2 ou L1.
Auto-encodeur contractuel
Cet auto-encodeur dispose de la même architecture constituée d’un encodeur, d’un espace latent et d’un décodeur. Néanmoins, à la différence de ceux que nous avons vus précédemment, ici, le code doit être similaire aux entrées et aux sorties. Autrement dit, la variation de l’espace latent doit être mineure par rapport aux données d’entrée.
L’auto-encodeur concret
Un auto-encodeur concret consiste à sélectionner des caractéristiques spécifiques pour l’espace latent. En guise encodeur, il utilise donc une couche de sélection concrète tandis que le décodeur reste un réseau de neurones standard. Pour mettre ce type d’algorithme, il suffit d’ajouter quelques lignes de code à un auto-encodeur classique.
L’auto-encodeur variationnel
Un auto-encodeur variationnel fonctionne d’une manière différente que les autres algorithmes. En termes simples, la représentation attendue correspond à l’espace latent ou au bottleneck. Les attributs latents sont exprimés sous forme de distribution de probabilité.
Quelles sont les utilisations d’un auto-encodeur ?
Bien que nous ayons mentionné quelques applications des auto-encodeurs dans les parties précédentes de l’article, nous allons voir tout cela plus en détail.
La réduction de dimensionnalité
La réduction de la dimensionnalité constitue l’une des premières utilisations de l’auto-encodeur depuis les années 1980. Bien que l’ACP soit une excellente procédure, elle ne permet pas une réduction non linéaire. De ce fait, un auto-encodeur under-complete permet d’encoder rapidement les données sans perdre trop d’informations. Par ailleurs, la réduction de la dimensionnalité permet de placer les échantillons sémantiquement de manière à faciliter les tâches comme la classification.
Le Débruitage d’images
Un auto-encodeur, notamment débruiteur, permet d’effectuer un débruitage d’images efficace et précis. Au lieu d’identifier le bruit, comme le font les autres méthodes, il extrait l’image originale grâce à une représentation de celle-ci. Cette représentation qui correspond à l’espace latent est ensuite compressée pour former une image bruitée.
Outre le débruitage, un auto-encodeur peut également avoir d’autres applications en termes de traitement d’images. Nous pouvons citer la compression avec perte ou encore pour la microscopie à super-résolution.
La génération de données d’images
Avec un auto-encodeur de type variationnel, la loi de la probabilité permet de paramétrer l’espace latent de manière aléatoire. Cela permet alors de générer des valeurs discrètes pour les attributs latents que le décodeur peut traduire en données d’images ou d’autres séries de données comme les séries temporelles.
La détection d’anomalies
Pour finir, un auto-encodeur est principalement entraîné à reconstruire un jeu de données grâce à l’apprentissage de caractéristiques spécifiques. Cela signifie que si le décodeur observe des caractéristiques non familières dans les attributs latents, il échouera à les reconstruire. De ce fait, les attributs inconnus sont considérés comme des anomalies.
- Partager l'article :

